
- Solve real problems with our hands-on interface
- Progress from basic puts and calls to advanced strategies
Interactive Options Course

Posted July 9, 2024 at 11:59 am
The article “Build a Warren Buffett Chatbot using OpenAI’s API” first appeared on AlgoTrading101 blog.
Excerpt
Note that this article does not refer to custom GPTs. Using custom GPTs, it is possible to build a Warren Buffett chatbot without code. Learn more about custom GPTs here.
Table of contents:
First, we will collect data on Warren Buffett’s market knowledge via video interviews. Next, we will clean and process this data. Lastly, using OpenAI’s API, we will fine-tune our own ChatGPT model by training it on the prepared data.
OpenAI is an American artificial intelligence research laboratory that is primarily focused on NLP tasks through using Large Language Models (LLMS) such as ChatGPT, Whisper, and the like.
Link to website: https://openai.com
ChatGPT is an LLM developed by OpenAI that is used for solving a wide range of tasks ranging from finance to bedtime stories.
Link to website: https://chat.openai.com
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. It is great for transcription and similar tasks.
Link to repo: https://github.com/openai/whisper
StableWhisper is an alteration of OpenAI’s Whisper model that produces more reliable timestamps.
The issue with the original Whisper is that it is prone to overshoot segments and thus produce unreliable timestamps that end up with sentences being cut up halfway and similar. This isn’t a big issue if we want to do summaries but for diarization, it reduces our accuracy.
There are procedures that can make these realignments on the original Whisper output such as using Wav2Vec2, and different punctuation models. Depending on your use case, this might be overkill and I’ve opted for using StableWhisper that doesn’t solve all the issues but helps considerably.
Link to the repo: jianfch/stable-ts: ASR with reliable word-level timestamps using OpenAI’s Whisper (github.com)
This article will have the goal of creating an AI Chatbot that will simulate chatting with Warren Buffett with ChatGPT.
To achieve such a goal, we will need to do several things that will be laid out below:
The amount of data that we will be using in this article won’t be too much so that the reader can follow the article without issues and also for brevity.
The audios that we will use are these three YouTube videos that are picked semi-randomly where Warren Buffett was interviewed or hosted:
Each video is different and will present its own challenge. The difference between videos 1 and 2 is that the interviewers are of different sexes which results in the male voice being more “similar” to Warren’s which could pose a threat to the diarization accuracy.
The third video is very long and has many speakers and it showcases the issue that these models face for panel formats of discussion.
When it comes to text data, for best results it would require a different treatment and use of a vector database which I’ll show in another article.
One thing to note is that you can easily extend the training data by adding more videos to it. You can also add other types of personas such as Soros and thus combine a hybrid value investor and macro trader.
You could also split the data to get different versions of Warren Buffett such as the one previous to the year X and the other after.
For this, I’ll be using my own PC that has an ASUS ROG Strix RTX3060 12GB GPU. For those that don’t have a GPU or have a weaker one, I suggest using Kaggle or Google Colab as they offer free ones.
Now that we have covered the main points, let us work with the videos.
Make sure that you have a fresh environment to work in. I usually use conda:
conda create -n buffett
Diarization is a process in speech processing that involves identifying and segmenting different speakers in an audio recording. Essentially, it’s about determining “who spoke when” which is useful for tasks such as transcribing multi-speaker conversations.
To perform diarization and prescription with Whisper, we will need to use another approach as Whisper sadly doesn’t perform diarization out-of-the-box at the time of writing.
Moreover, we will be using the StableWhisper library and not the original Whisper one to gain on performance.
There are only a couple of diarization projects out there with mixed results. It seems that there aren’t a lot of contributions to the diarization process overall (well, at least open-source ones) that solve the problem with high accuracy.
I tried out a few of them such as the pyannote gated HuggingFace model and have found that it doesn’t perform better than a simple clustering pipeline I wrote. I found one HugginFace project and refactored it as the code for it wasn’t the best and was kept strictly inside HuggingFace.
The refactored version that can perform both transcription and diarization can be found on our AlgoTrading101 GitHub repository and can easily be used and cloned into Kaggle, Google Colab, locally and etc.
The project features a Gradio UI and has improved and cleaned code from its original version which can be found on HugginFace which wasn’t coded by me. My version features a more accurate diarization process, more accurate transcriptions and timestamps, and other quality improvements.
It was a quick refactor, and PRs are welcome.
You can also use the HuggingFace version and skip the bottom installation header part but it often fails for me.
We’ll start by installing the prerequisites that will ensure that you can use the above repo. First, clone the repo and install its requirements in a fresh environment that we created.
$ git clone https://github.com/AlgoTrading101/AlgoTrading101-Warren-Buffett-ChatGPT.git $ pip install -r requirements.txt $ pip install -qq https://github.com/pyannote/pyannote-audio/archive/refs/heads/develop.zip
After that, create a .env file in the root of the repository by following the example template in env.example. The most important variable is to set your HUGGINGFACE_TOKEN as this will be needed to get the models that we will use from HuggingFace.
If you don’t have a token, please navigate to their website and create an account by clicking the “Sign Up” button in the upper right corner.

When you log into your account, click on your account icon in the upper right corner and navigate to Settings and then on the left menu click Access Tokens.
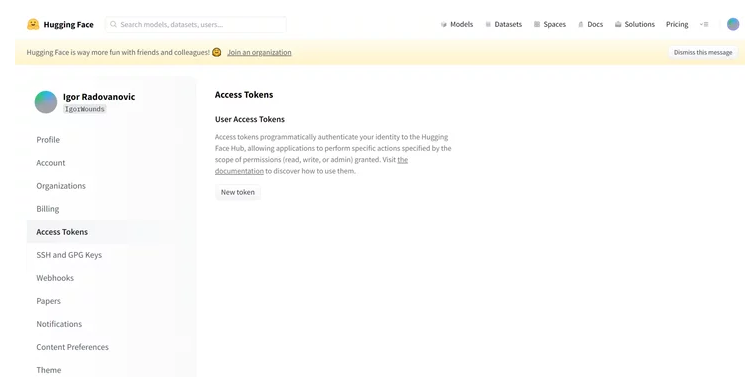
There you can create a new token with “read” permissions and paste it into your env.
The next two things are only for users that want to run this locally. Ensure that you have ffmpeg installed. To quickly check for this open up a terminal and run ffmpeg. If you don’t see anything popping up with the version number and similar, there is an installation guide for each major OS here.
Because we are using PyTorch, you will probably want to re-install it with your adequate version of Cuda by using this link here. I will rely on the CUDA that conda provides by following this link over here and selecting the latest supported version:
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
To see up to which version your GPU supports the CUDA, you can run this command and read the version number in the upper right corner:
nvidia-smi
To start the Gradio UI, we run the following (if you face issues with HuggingFace, I suggest running it as an administrator for the first time so it can pull the models easily):
python main.py
Now navigate to this URL to access it: https://127.0.0.1:7860/
If you want all of this inside a notebook, you can move the contents of main.py into a notebook and run it that way.
We begin our transcription and diarization process by pasting our YouTube video URL and then clicking the “Download YouTube video” button. After the video has been downloaded, you will be able to play it to confirm that it is functional.
Note: If the video is too long, sometimes it won’t appear straight away as it is being rendered and you can check if it is downloaded by observing your file structure or console output. But, you still need to wait for it to appear in order to continue the process. This can take some time depending on the video length.
The next step is to select the Whisper model you want to use, and the assumed number of speakers in the video.
The model that I suggest using is the large-v2 one as it offers the best transcription accuracy and segmentation. I’ve tried the lower ones and they had mixed accuracy results. The base one is also fine.
The goal of this article is to show you what you can do and how to do it. You can bring in more advanced pipelines and experiment with different models and use cases.
When it comes to the number of speakers, if you set it to 0 speakers, it will try to dynamically infer the number of speakers. It is not the best at doing it so I suggest setting this number if you know it or aren’t too lazy to check as the dynamic recognition needs improvements to be more precise.
It can also be an assumed number of speakers.
Now, click the “Transcribe audio and diarization” button and watch the magic happen. When it completes, and it usually doesn’t take too long, you will see your dataset at the bottom of the page. You will also be able to find its CSV in the output folder.
The diarization works by applying three clustering algorithms (KMeans, Agglomerative Clustering, and a Gaussian Mixture Model) on the audio segment embeddings and labeling the segment with a vote where 2/3 algorithms agreed.
This ensures the higher accuracy of the diarization and avoids relying on just one algorithm. I’ve found this approach to work well and it doesn’t require the usage of fancy neural networks and similar big models.
If you are using this on a Cloud or the like, you can also download the output to your local computer by pressing the download button inside the UI.
The dataset will have your transcript with adequate timestamps and speaker(s).
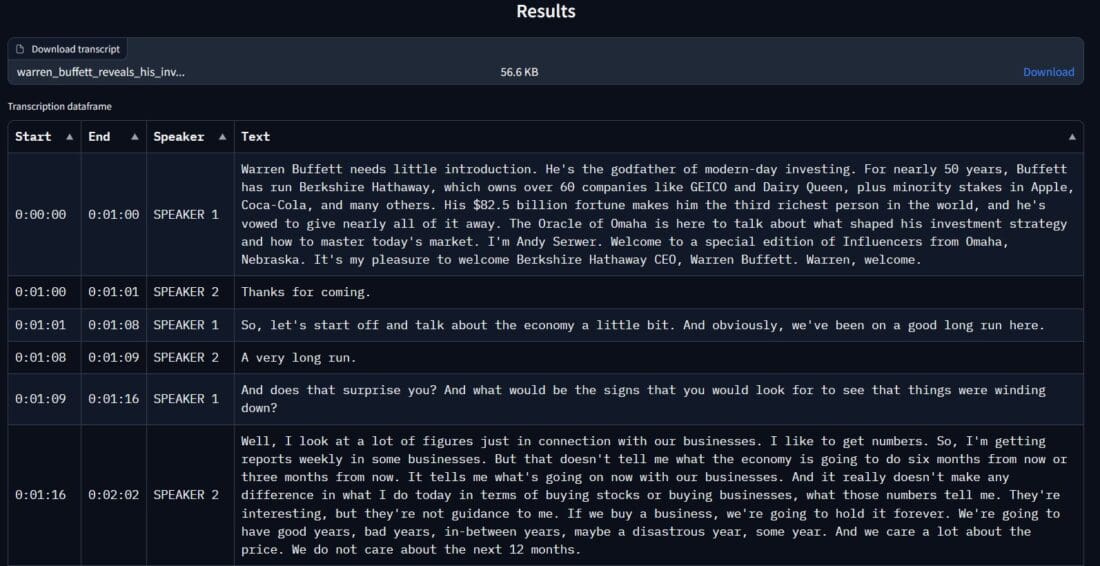
In the Full code section of this article, you will find all the datasets inside the output folder of our repo.
When it comes to (pre/post)processing your videos and transcripts, you can cut out the parts from the videos where Warren Buffett wasn’t a part of the conversation as you can argue that we don’t need those.
This is the case for the last video labeled with the number 3 in which Buffett started speaking around the 1 hour mark. Thus, we will need to intercept the workflow. I’ll trim the part up to the 1-hour mark and split the remainder into 4 parts so that it can fit into my memory without issues.
The next thing that I’ll do for all transcripts is to deal with the fact that even the StableWhisper overshoots or undershoots a peculiar segment which can mess with the diarization clustering algorithms as they get leakage from its neighboring segment which can result in interesting results.
To combat this and increase accuracy I will create a cleaning pipeline that will check if a sentence is stopped midway and tape it back together where it is obvious. For example, ending a sentence with a comma, next row starting with a lowercase word or number, etc.
We will also merge the speaker into one if it repeats for two or more rows. The pipeline can be found inside the clean.ipynb notebook and is an optional but recommended step. Feel free to think of ways to improve this pipeline and make it more robust.
To completely fix the Whisper issue, we would need more heavy AI algorithms that I’ve mentioned before. As improved models of Whisper and diarization algorithms come out, this will be less of an issue.
Now that the datasets are cleaned, I will rename the speaker columns into “BUFFETT” where it makes sense and merge all datasets into a single one. I will also do some manual cleaning as Buffett stutters can mess up the segments and overall diarization.
Visit AlgoTrading101 blog to read about ChatGPT finetuning.
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from AlgoTrading101 and is being posted with its permission. The views expressed in this material are solely those of the author and/or AlgoTrading101 and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.










Join The Conversation
For specific platform feedback and suggestions, please submit it directly to our team using these instructions.
If you have an account-specific question or concern, please reach out to Client Services.
We encourage you to look through our FAQs before posting. Your question may already be covered!