
- Solve real problems with our hands-on interface
- Progress from basic puts and calls to advanced strategies
Interactive Options Course

Posted May 30, 2023 at 10:48 am
This post will go through how to create a word cloud of article titles scraped from the awesome R-bloggers. Our goal will be to use R’s rvest package to search through 50 successive pages on the site for article titles. The stringr and tm packages will be used for string cleaning and for creating a term document frequency matrix (with tm). We will then create a word cloud based off the words comprising these titles.
First, we’ll load the packages we need.
# load packages library(rvest) library(stringr) library(tm) library(wordcloud)
Let’s write a function that will take a webpage as input and return all the scraped article titles.
scrape_post_titles <- function(site)
{
# scrape HTML from input site
source_html <- read_html(site)
# grab the title attributes from link (anchor) tags within H2 header tags
titles <- source_html %>% html_nodes("h2")
%>% html_nodes("a")
%>% html_attr("title")
# filter out any titles that are NA (where no title was found)
titles <- titles[!is.na(titles)]
# parse out just the article title (removing the words "Permalink to ")
titles <- gsub("Permalink to ", "", titles)
# return vector of titles
return(titles)
}The above function takes an input, called site, which will be the URL of a specific webpage on R-bloggers. We then use rvest’s read_html function to scrape the HTML from the webpage. Next, we parse out the titles by searching through the H2 tags, and parsing out the title attributes from the links within those header tags i.e. we search through each H2 tag, find the “a” tag (anchor, or link), and then pull the title from that tag.
The remaining code above is for cleaning up the titles we parsed. We take out any titles we parsed that are NA – i.e. any link tags that did not have a title attribute (these are not post titles). At this point, each of the title attributes we have has the words “Permalink to “. The gsub line of code is just getting rid of this in each title.
#filter out any titles that are NA (where no title was found)
titles <- titles[!is.na(titles)]
# parse out just the article title (removing the words "Permalink to ")
titles <- gsub("Permalink to ", "", titles)Now, let’s get the vector of webpages we need to scrape. Each successive page containing article links has the following pattern:
“https://www.r-bloggers.com/page/index” where index is some positive integer.
https://www.r-bloggers.com/page/1
https://www.r-bloggers.com/page/2
https://www.r-bloggers.com/page/3
https://www.r-bloggers.com/page/4
…
…
…
Thus, we can just use the paste0 function to generate all the URLs we want.
root <- "https://www.r-bloggers.com/" # get each webpage URL we need all_pages <- c(root, paste0(root, "page/", 2:50))
Next, let’s scrape the post titles from each webpage using our scrape_post_titles function. Then, we’ll collapse the titles into a single vector.
# use our function to scrape the title of each post all_titles <- lapply(all_pages, scrape_post_titles) # collapse the titles into a vector all_titles <- unlist(all_titles)
After we have the titles scraped, we need to perform some cleaning operations, such as converting each title to lowercase, and getting rid of numbers, punctuation, and stop words.
## Clean up the titles vector
#############################
# convert all titles to lowercase
cleaned <- tolower(cleaned)
# remove any numbers from the titles
cleaned <- removeNumbers(cleaned)
# remove English stopwords
cleaned <- removeWords(cleaned, stopwords("en"))
# remove punctuation
cleaned <- removePunctuation(cleaned)
# remove spaces at the beginning and end of each title
cleaned <- str_trim(cleaned)Next, we use the tm package to convert our cleaned vector of titles to a corpus. On the next line, we stem each word in the titles to get the root of each word (e.g. model, models, and modeling will each count as the same word, model).
# convert vector of titles to a corpus cleaned_corpus <- Corpus(VectorSource(cleaned)) # steam each word in each title cleaned_corpus <- tm_map(cleaned_corpus, stemDocument)
With the cleaned corpus, we can get a term document matrix. This will give us a frequency of how often each word occurs.
doc_object <- TermDocumentMatrix(cleaned_corpus)
doc_matrix <- as.matrix(doc_object)
# get counts of each word
counts <- sort(rowSums(doc_matrix),decreasing=TRUE)
# filter out any words that contain non-letters
counts <- counts[grepl("^[a-z]+$", names(counts))]
# create data frame from word frequency info
frame_counts <- data.frame(word = names(counts), freq = counts)Lastly, we use the wordcloud package to generate a word cloud based off the words across all the titles.
set.seed(1000)
wordcloud(words = frame_counts$word, freq = frame_counts$freq, min.freq = 1,
max.words=200, random.order=FALSE, rot.per=0.2,
colors=brewer.pal(8, "Dark2"))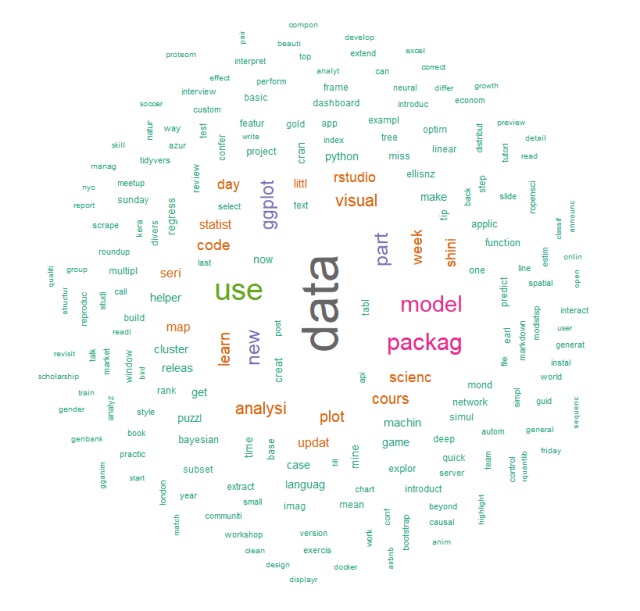
Above, we can see that “data” is the most popular word. Variations of “model”, “analysis”, and “package” are also popular.
Originally posted on TheAutomatic.net blog.
For specific platform feedback and suggestions, please submit it directly to our team using these instructions.
If you have an account-specific question or concern, please reach out to Client Services.
We encourage you to look through our FAQs before posting. Your question may already be covered!
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from TheAutomatic.net and is being posted with its permission. The views expressed in this material are solely those of the author and/or TheAutomatic.net and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.











EY는 기술, 지정학적 요인, 지속가능성, 인구구조 등 변화를 야기하는 근본 원인들을 분석함으로써, 우리의 미래를 재편할 주요 메가트렌드를 식별하고
있습니다.