
- Solve real problems with our hands-on interface
- Progress from basic puts and calls to advanced strategies
Interactive Options Course

Posted November 12, 2024 at 12:53 pm
The basic Vector Autoregression (VAR) model is heavily used in macro-econometrics for explanatory purposes and forecasting purposes in trading. In recent years, a VAR model with time-varying parameters has been used to understand the interrelationships between macroeconomic variables. Since Primiceri (2005), econometricians have been applying these models using macroeconomic variables such as:
This article extends the model usage to something our audience greatly cares about: trading! You’ll learn the basics of the estimation procedure and how to create a trading strategy based on the model.
Are you excited? I was when I started writing this article. Let me share what I’ve learned with you!
All the explanations of the basic VAR can be found in our previous article. Here, we’ll provide the system of equations and compare them with our new model.
Let’s remember the basic model. For example, a basic bivariate VAR(1) can be described as a system of equations:
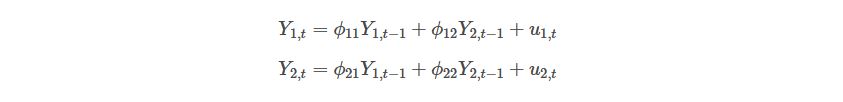
Or,

Where

A time-varying parameter VAR would be something like the following:
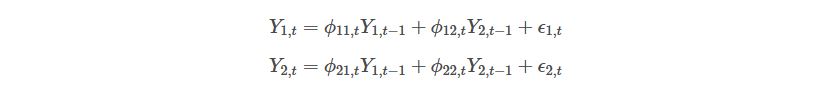
Do you get to see the difference between the two models? Not yet?
Let’s use matrices to see it clearly.
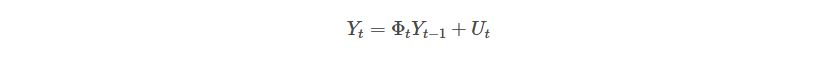
Where:
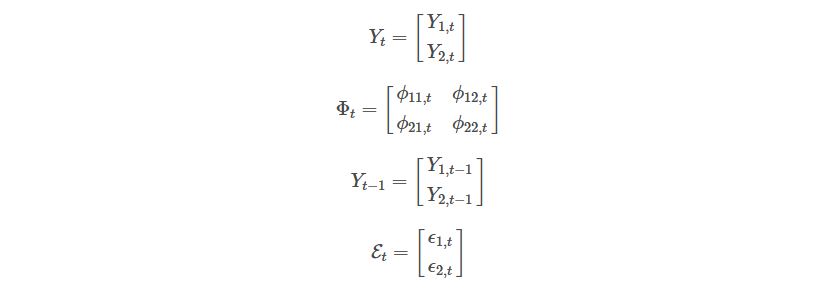
Now you see it?
The only difference is that the model’s parameters vary as time passes. Hence, it’s referred to as a “time-varying-parameter” model.
Even though the difference appears simple, the estimation procedure is much more complex than the basic VAR estimation.
You now say: I know we can have time-varying parameters, but where is the stochastic volatility in the previous equations?
Wait for it, my friend! We’ll see it later!
Don’t worry, we’ll keep it simple!
Using a new notation provided by Primiceri (2005):
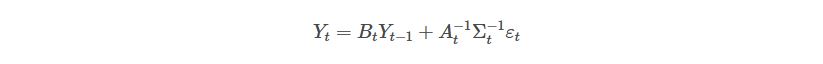
Where:
Y: The vector of time series
B: The parameters of the lagged time series of this reduced model
A: The contemporary parameters of the time series vector
Sigma: The time-varying standard deviation (volatility) of each equation in the VAR.
Epsilon: A vector of shocks of each equation in the VAR.
Well, in macroeconometrics, the reduced model can be understood as a simple VAR as modeled in our previous article. In this model, today’s time series values of the VAR vector are impacted only by their lag versions.
However, economists also talk about the impact that the same today’s time series values have on each other today’s time series values. This can be modeled as:
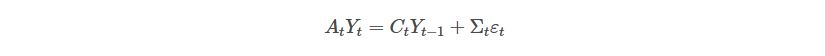
This can shown as a matrix below:

Which can also be presented as a system of equations:

The above model is understood in econometrics as a structural model to comprehend the time series interrelationships, contemporary or not, between the time series analyzed.
So, assuming we have daily data, the first question, which belongs to y1, has a12*y2 as today’s y2 impact on today’s y1. The same is true for the second question, which belongs to y2, where we see a21*y1, which is today’s time series y1 impact on y2. In a VAR, we have lag periods impacting today’s variables, in a structural VAR we have today’s variables impacting today’s other variables.
Due to these contemporary relationships, there is a problem called endogeneity, where the error terms epsilons are correlated with Y_t-1. To estimate a structural VAR, we need to clearly identify the matrix A variables. As Eric (2021) explained, there are 3 ways in the economic literature. But it’s not only that, as per this model, A is also time-varying. We’ll see later how this variables are estimated.
When you pre-multiply the system of equations by A^-1, you get something like:
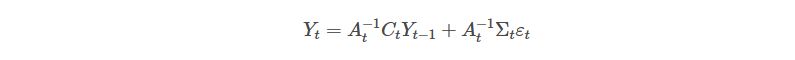
Which can be further simplified as:
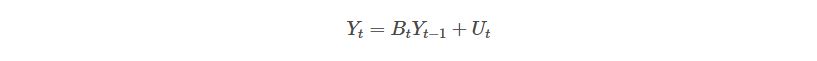
So,
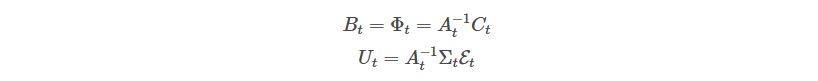
Yes! In a basic VAR, the error terms are homoskedastic, meaning, they present constant variance. In this case, we have variances that change over time; they’re time-variant.
The basic VAR had its parameters constant. In this TVP-VAR-SV, we have almost all of our parameters time-variant. Due to this, we need to assign them stochastic processes. As in Primiceri (2005), we define them as:
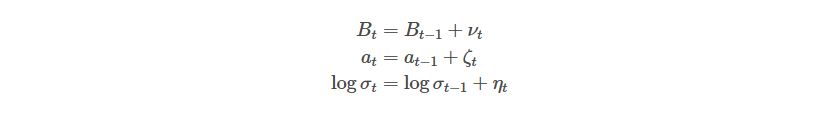
We can then specify the matrix of variances of all the model’s shocks as:
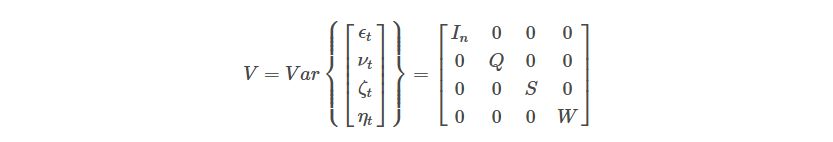
Where I_n is the identity matrix and n is the number of time series in the VAR (in our case it’s 2). Q, S, and W are square positive-definite covariance matrices with a number of rows (or columns) equal to the number of parameters in B, A, and Sigma, respectively.
Something else to note: sigma is stochastic-based, which can be interpreted as stochastic volatility as, e.g., the Heston model is.
For a Bayesian inference, you always need priors. In the Primiceri (2005) algorithm, the priors are computed using your data sample’s first “T1” observations.
Using our previously defined variables, you can specify the priors (following Primiceri, 2005, and Del Negro and Primiceri, 2015):
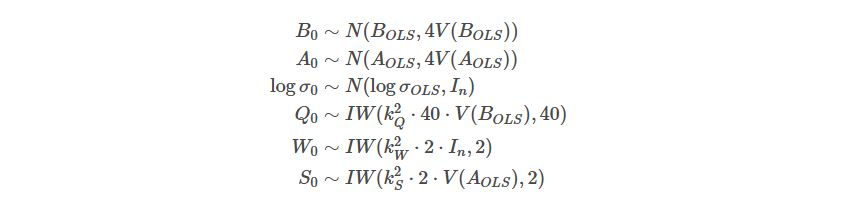
Where
Once you estimate the priors with the first T1 observations, then you get the posterior distribution using the rest of the data sample.
Before we dive into the algorithm, let’s learn something else. Do you remember the reduced-form model:
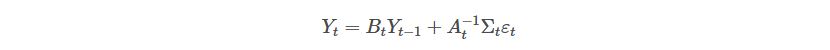
To clear the error term, we get

Primiceri (2005), appendix A.2 explains that the above model has a Gaussian non-linear state space representation. The difficulty with drawing Sigma_t is that they enter the model multiplicatively.
This presents the issue of not making it easy for the Kalman filter estimation done inside the whole estimation algorithm (The Kalman filter is linear-based). To overcome this issue, Primiceri (2005) applies squaring and takes the logarithms of every element of the previous equation. As a consequence of this transformation, the resulting state-space form becomes non-Gaussian, because the log(epsilon_t^2) has a log chi-squared distribution. To finally get a normal distribution for the error terms, Kim et al. (1998) use a mixture of normals to approximate each element of log(epsilon_t^2). Thus, the estimation algorithm uses the mixture indicators for each error term and each date.
Stay tuned for the next installment to read about the TVP-VAR-SV model estimation algorithm.
Originally posted on QuantInsti blog.
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from QuantInsti and is being posted with its permission. The views expressed in this material are solely those of the author and/or QuantInsti and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.









Join The Conversation
For specific platform feedback and suggestions, please submit it directly to our team using these instructions.
If you have an account-specific question or concern, please reach out to Client Services.
We encourage you to look through our FAQs before posting. Your question may already be covered!