
- Solve real problems with our hands-on interface
- Progress from basic puts and calls to advanced strategies
Interactive Options Course

Posted July 1, 2026 at 11:00 am
The article “A Poor Person’s Transformer” was originally published on PredictNow.ai.
For those of us who grew up before GenAI became a thing (e.g. Ernie), we often use tree-based algorithms for supervised learning. Trees work very well with heterogeneous and tabular feature sets, and by limiting the number of nodes or the depth of a branch, there is feature selection by default. With neural networks (NN), before deep learning came around, it was quite common to perform feature selection using L1 regularization – i.e. adding a L1 penalty term to the objective function in order to encourage some of the network parameters to become zero. However, L1 regularizations are quite tedious when we have millions or billions of parameters in a deep neural network. In its place, transformers and attention became the go-to technique for feature selection in a deep neural network (see Chapter 5 of our book.) But beyond making feature selection practical for DNN, the attention mechanism provides one important benefit that is absent from traditional regularization or feature selection methods (such as MDA, SHAP, or LIME, see Chan & Man https://arxiv.org/abs/2005.12483): the selected features depend on each sample. They aren’t selected globally like traditional feature selection methods do. In other words, the features are selected based on their values themselves. In the language of transformers, we use self-attention for feature selection.
Transformers are usually illustrated with textual input. For e.g., a sentence containing 4 features (words/tokens) “I”, “am”, “a”, “student”. Let’s call this input feature vector X. In DNN, each feature may be a vector (e.g. we may use a d-dimensional vector to represent a word/token), as opposed to a scalar. So X may actually have dimension n × d, where n is the number of features (not the number of samples!) and d is the dimension of each feature. A financial application where this can be useful is when one feature (row) vector captures the daily return of a stock, its P/E, dividend yield, …, up d types of features, at a snapshot in time t. Another feature vector captures the same information at time t-1, and so on, up to a lookback of n. So if you have n lookback periods, the feature matrix has dimension n × d. But in many financial applications, each feature is just a real-valued scalar such as the daily return of a single stock. So X=[r(t), r(t-1), …, r(t-n+1)]T. This is the simple example we will use in our Poor Person’s version of transformer: d=1, and X is just a column vector with dimension n × 1.
Now, in ordinary transformers, the next step is to transform X into 3 different vectors / matrices: Q (query, with width dq), K (key, with height dk), and V (value, with height dv). An element in Q is like “what this feature is looking for in other features that can provide as context”, an element in K is like “this is the context that this feature can provide, and element in V is like “this is a feature in a new representation”.
In a typical transformer with self-attention, for each input vector X, the Q, K and V values are calculated as linear transformation of X:
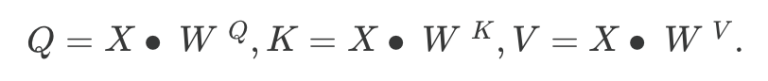
The WQ, WK, WV matrices themselves are learned parameters, learned based on the ultimate objective of this NN (e.g. classification, regression, or optimization), but the resulting attention score is computed as the function of the input sample X. The W’s all have heights n, but widths dq, dk, and dv respectively, though dq, dk are often set to be the same dimension. The intuition behind these Q, K, V is we want some linear mixtures of the original feature matrix X that best represent it, reminiscent of the familiar PCA. In the example of the n × d financial feature matrix we described above, we want to linearly project the return and fundamentals of a stock to some “principal component” vector, while preserving the distinctness of each lagged snapshot of these features since the projection is row-wise. I.e. Q, K, V have same height as X and so each row still represents a specific snapshot in time, as seen in the figure below which illustrates the building blocks of a transformer with self-attention.
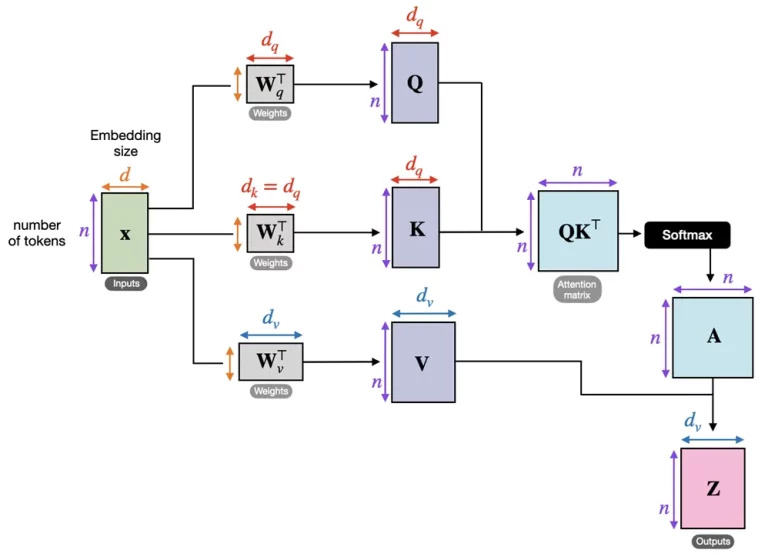
Source: https://sebastianraschka.com/blog/2023/self-attention-from-scratch.html
The figure below shows specifically a transformer with n=4, d=4, and dq=dk=dv=2. It shows also how the Q and K matrices are multiplied together, scaled by sqrt(dk) to prevent the magnitude from exploding, and fed through a softmax function to turn them into attention scores in [0, 1], in a process called “Scaled Dot-Product Attention” (for more details, see again Chapter 5 of our book).
Why sqrt(dk)? We will quote Cong et. al. “Assume that the components of q and k are independent random variables with mean 0 and variance 1. Then their dot product,

has mean 0 and variance dk. Why softmax? Softmax function normalizes the scaled dot-product into a matrix where each row is the normalized weights (i.e. they sum to 1) which are the attention weights applicable to the feature value matrix V. To wit,
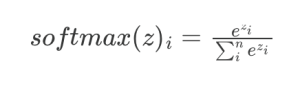
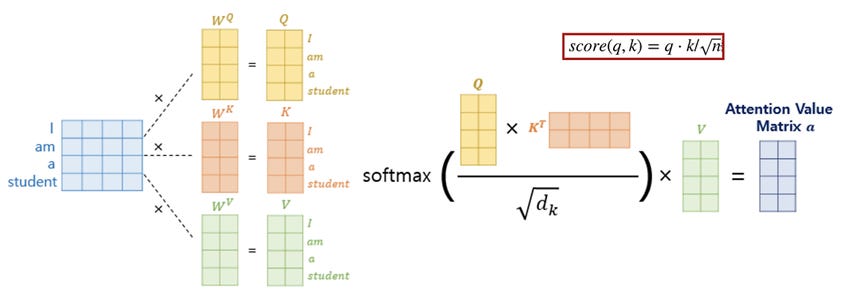
Source: https://sebastianraschka.com/blog/2023/self-attention-from-scratch.html. Here n=4, d=2.
But, in our Poor Person’s transformer, W is just a scalar, and Q, K, and V are all just 1-dimensional vectors. So we might as well eliminate this step and replace them all by the vector X. Note that this doesn’t collapse the matrix QKT into a scalar or vector. It is still a n × n matrix formed by XXT. Each feature i is still multiplying feature j to form the attention matrix element A(i, j). The elements of each row of A sums to 1 as in all attention matrices. If you ask “What is the feature importance score of feature j”, you can sum over all the values of column j, since column j represents the key feature j.
So if feature importance scores or feature selection are all you are after, we are done. But usually we are interested in downstream applications. In our 1 stock n-returns example, we might be interested in using these n daily returns, with proper feature weights, to predict the next day’s return. In this case, all we need to do it to multiply the attention matrix with V, which in our case is equal to X, to create the “context vector” Z=AV=AX. The context vector is an attention-weighted version of our original feature vector X. Downstream, we can use Z as input to a MLP for supervised learning, such as predicting the next day’s return, or for optimization via reinforcement learning.
Does this work? You can ask ChatGPT or some other favorite chatbot to create a program based on this blog post and try it out. Let us know how the results look in the comments!
P.S.
You may get excited by this feature selection method and think we should throw in a bunch of “heterogeneous” features such as volatility, P/E, earning yield, … of the stock to see if they work better. Unfortunately, the Poor Person’s self-attention method discussed above doesn’t work very well with features that cannot embedded in the same space. For example, it is nonsensical to add together A(i, j)=volatility * P/E and A(i+1, j)=dividend * P/E to form the feature importance score of P/E. To do that, we need to do some normalization and embedding. Also, maybe we want to tell the transformer that r(t), r(t-1), … is a time series and the features are time-ordered. All topics for the next blog post!
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from PredictNow.ai and is being posted with its permission. The views expressed in this material are solely those of the author and/or PredictNow.ai and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.
The third-party code discussed within this article is not investment or trading advice, and is for proof-of-concept, educational, and illustrative purposes only. IBKR makes no representations or warranty regarding its accuracy or completeness. Users are solely responsible for conducting their own independent testing and due diligence before applying any code or concepts in a live or production environment










Join The Conversation
For specific platform feedback and suggestions, please submit it directly to our team using these instructions.
If you have an account-specific question or concern, please reach out to Client Services.
We encourage you to look through our FAQs before posting. Your question may already be covered!