
- Solve real problems with our hands-on interface
- Progress from basic puts and calls to advanced strategies
Interactive Options Course

Posted June 17, 2025 at 12:08 pm
The article “Reinforcement Learning in Trading” was originally posted on QuantInsti blog.
Initially, AI research focused on simulating human thinking, only faster. Today, we’ve reached a point where AI “thinking” amazes even human experts. As a perfect example, DeepMind’s AlphaZero revolutionised chess strategy by demonstrating that winning doesn’t require preserving pieces—it’s about achieving checkmate, even at the cost of short-term losses.
This concept of “delayed gratification” in AI strategy sparked interest in exploring reinforcement learning for trading applications. This article explores how reinforcement learning can solve trading problems that might be impossible through traditional machine learning approaches.
Before exploring the concepts in this blog, it’s important to build a strong foundation in machine learning, particularly in its application to financial markets.
Begin with Machine Learning Basics or Machine Learning for Algorithmic Trading in Python to understand the fundamentals, such as training data, features, and model evaluation. Then, deepen your understanding with the Top 10 Machine Learning Algorithms for Beginners, which covers key ML models like decision trees, SVMs, and ensemble methods.
Learn the difference between supervised techniques via Machine Learning Classification and regression-based price prediction in Predicting Stock Prices Using Regression.
Also, review Unsupervised Learning to understand clustering and anomaly detection, crucial for identifying patterns without labelled data.
This guide is based on notes from Deep Reinforcement Learning in Trading by Dr Tom Starke and is structured as follows.

Despite sounding complex, reinforcement learning employs a simple concept we all understand from childhood. Remember receiving rewards for good grades or scolding for misbehavior? Those experiences shaped your behavior through positive and negative reinforcement.
Like humans, RL agents learn for themselves to achieve successful strategies that lead to the greatest long-term rewards. This paradigm of learning by trial-and-error, solely from rewards or punishments, is known as reinforcement learning (RL).
In trading, RL can be applied to various objectives:
The distinguishing advantage of RL is its ability to learn strategies that maximise long-term rewards, even when it means accepting short-term losses.
Consider Amazon’s stock price, which remained relatively stable from late 2018 to early 2020, suggesting a mean-reverting strategy might work well.
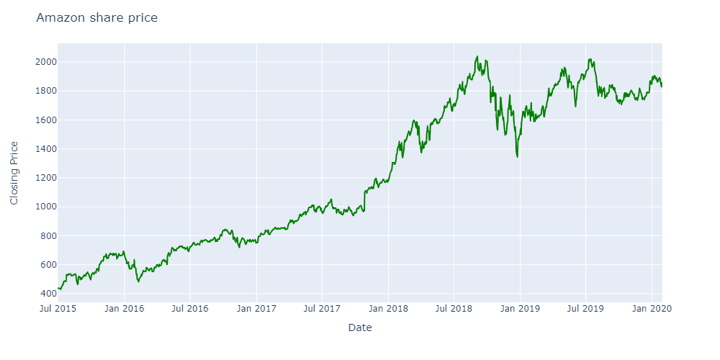
Source: Yahoo Finance
However, from early 2020, the price began trending upward. Deploying a mean-reverting strategy at this point would have resulted in losses, causing many traders to exit the market.
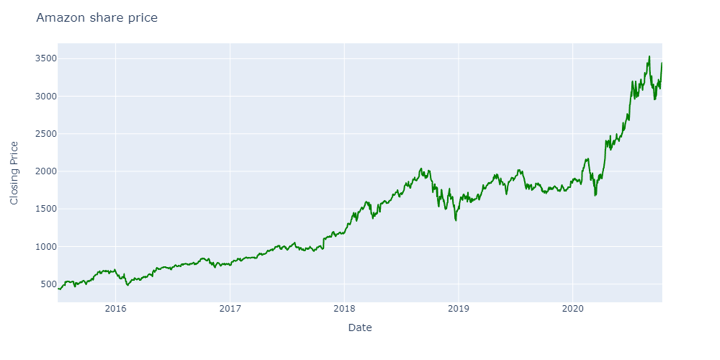
Source: Yahoo Finance
An RL model, however, could recognise larger patterns from previous years (2017-2018) and continue holding positions for substantial future profits—exemplifying delayed gratification in action.
Unlike traditional machine learning algorithms, RL doesn’t require labels at each time step. Instead:
Traditional ML requires labels at specific intervals (e.g., hourly or daily) and focuses on regression to predict the next candle percentage returns or classification to predict whether to buy or sell a stock. This makes solving the delayed gratification problem particularly challenging through conventional ML approaches.
This guide focuses on the conceptual understanding of Reinforcement Learning components rather than their implementation. If you’re interested in coding these concepts, you can explore the Deep Reinforcement Learning course on Quantra.
Actions define what the RL algorithm can do to solve a problem. For trading, actions might be Buy, Sell, and Hold. For portfolio management, actions would be capital allocations across asset classes.
Policies help the RL model decide which actions to take:
In trading, it is crucial to maintain a balance between exploration and exploitation. A simple mathematical expression that decays exploration over time while retaining a small exploratory chance can be written as:
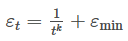
Here, εₜ is the exploration rate at trade number t, k controls the rate of decay, and εₘᵢₙ ensures we never stop exploring entirely.
The state provides meaningful information for decision-making. For example, when deciding whether to buy Apple stock, useful information might include:
All this information constitutes the state. For effective analysis, the data should be weakly predictive and weakly stationary (having constant mean and variance), as ML algorithms generally perform better on stationary data.
Rewards represent the end objective of your RL system. Common metrics include:
When it comes to trading, using just the PnL sign (positive/negative) as the reward works better as the model learns faster. This binary reward structure allows the model to focus on consistently making profitable trades rather than chasing larger but potentially riskier gains.
The environment is the world that allows the RL agent to observe states. When the agent applies an action, the environment processes that action, calculates rewards, and transitions to the next state.
The agent is the RL model that takes input features/state and decides which action to take. For instance, an RL agent might take RSI and 10-minute returns as input to determine whether to go long on Apple stock or close an existing position.

Let’s see how these components work together:
Step 1:
Step 2:
| Date | Closing price | Action | Reward (% returns) |
| Jan 24 | $92 | Buy | – |
| Jan 27 | $94 | Sell | 2.1 |
At each time step, the RL agent needs to decide which action to take. The Q-table helps by showing which action will give the maximum reward. In this table:
Example Q-table:
| Date | Sell | Hold |
| 23-01-2025 | 0.954 | 0.966 |
| 24-01-2025 | 0.954 | 0.985 |
| 27-01-2025 | 0.954 | 1.005 |
| 28-01-2025 | 0.954 | 1.026 |
| 29-01-2025 | 0.954 | 1.047 |
| 30-01-2025 | 0.954 | 1.068 |
| 31-01-2025 | 0.954 | 1.090 |
On Jan 23, the agent would choose “hold” since its Q-value (0.966) exceeds the Q-value for “sell” (0.954).
Let’s create a Q-table using Apple’s price data from Jan 22-31, 2025:
| Date | Closing Price | % Returns | Cumulative Returns |
| 22-01-2025 | 97.2 | – | – |
| 23-01-2025 | 92.8 | -4.53% | 0.95 |
| 24-01-2025 | 92.6 | -0.22% | 0.95 |
| 27-01-2025 | 94.8 | 2.38% | 0.98 |
| 28-01-2025 | 93.3 | -1.58% | 0.96 |
| 29-01-2025 | 95.0 | 1.82% | 0.98 |
| 30-01-2025 | 96.2 | 1.26% | 0.99 |
| 31-01-2025 | 106.3 | 10.50% | 1.09 |
If we’ve bought one Apple share with no remaining capital, our only choices are “hold” or “sell.” We first create a reward table:
| State/Action | Sell | Hold |
| 22-01-2025 | 0 | 0 |
| 23-01-2025 | 0.95 | 0 |
| 24-01-2025 | 0.95 | 0 |
| 27-01-2025 | 0.98 | 0 |
| 28-01-2025 | 0.96 | 0 |
| 29-01-2025 | 0.98 | 0 |
| 30-01-2025 | 0.99 | 0 |
| 31-01-2025 | 1.09 | 1.09 |
Using only this reward table, the RL model would sell the stock and get a reward of 0.95. However, the price is expected to increase to $106 on Jan 31, resulting in a 9% gain, so holding would be better.
To represent this future information, we create a Q-table using the Bellman equation:
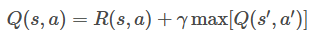
Where:
Starting with Jan 30’s Hold action:
Completing this process for all rows gives us our Q-table:
| Date | Sell | Hold |
| 23-01-2025 | 0.95 | 0.966 |
| 24-01-2025 | 0.95 | 0.985 |
| 27-01-2025 | 0.98 | 1.005 |
| 28-01-2025 | 0.96 | 1.026 |
| 29-01-2025 | 0.98 | 1.047 |
| 30-01-2025 | 0.99 | 1.068 |
| 31-01-2025 | 1.09 | 1.090 |
The RL model will now select “hold” to maximise Q-value. This process of updating the Q-table is called Q-learning.
In real-world scenarios with vast state spaces, building complete Q-tables becomes impractical. To overcome this, we can use Deep Q Networks (DQNs)—neural networks that learn Q-tables from past experiences and provide Q-values for actions when given a state as input.
These techniques address fundamental challenges in deep RL, improving efficiency, stability, and performance across complex environments.
While training, the RL model works in isolation without interacting with the market. Once deployed, we don’t know how it will affect the market. Type 2 chaos occurs when an observer can influence the situation they’re observing. Although difficult to quantify during training, we can assume the RL model will continue learning after deployment and adjust accordingly.
RL models might interpret random noise in financial data as actionable signals, leading to inaccurate trading recommendations. While methods exist to remove noise, we must balance noise reduction against a potential loss of important data.
We’ve introduced the fundamental components of reinforcement learning systems for trading. The next step would be implementing your own RL system to backtest and paper trade using real-world market data.
For a deeper dive into RL and to create your own reinforcement learning trading strategies, consider specialised courses in Deep Reinforcement Learning on Quantra.
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from QuantInsti and is being posted with its permission. The views expressed in this material are solely those of the author and/or QuantInsti and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.









Join The Conversation
For specific platform feedback and suggestions, please submit it directly to our team using these instructions.
If you have an account-specific question or concern, please reach out to Client Services.
We encourage you to look through our FAQs before posting. Your question may already be covered!