
- Solve real problems with our hands-on interface
- Progress from basic puts and calls to advanced strategies
Interactive Options Course

Posted November 4, 2024 at 11:36 am
The post “Train/Test Split and Cross Validation – A Python Tutorial” first appeared on AlgoTrading101 blog.
Excerpt
What is a training and testing split? It is the splitting of a dataset into multiple parts. We train our model using one part and test its effectiveness on another.
In this article, our focus is on the proper methods for modelling a relationship between 2 assets.
We will check if bonds can be used as a leading indicator for the S&P500.
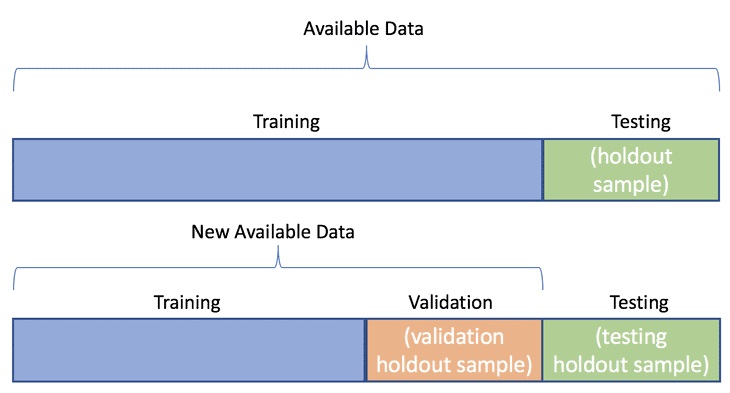
Data splitting is the process of splitting data into 3 sets:
If we do not split our data, we might test our model with the same data that we use to train our model.
Example
If the model is a trading strategy specifically designed for Apple stock in 2008, and we test its effectiveness on Apple stock in 2008, of course it is going to do well.
We need to test it on 2009’s data. Thus, 2008 is our training set and 2009 is our testing set.
To recap what are training, validation and testing sets…
The training set is the set of data we analyse (train on) to design the rules in the model.
A training set is also known as the in-sample data or training data.
The validation set is a set of data that we did not use when training our model that we use to assess how well these rules perform on new data.
It is also a set we use to tune parameters and input features for our model so that it gives us what we think is the best performance possible for new data.
The test set is a set of data we did not use to train our model or use in the validation set to inform our choice of parameters/input features.
We will use it as a final test once we have decided on our final model, to get the best possible estimate of how successful our model will be when used on entirely new data.
A test set is also known as the out-of-sample data or test data.
To prevent look-ahead bias, overfitting and underfitting.
Let’s illustrate this with an example.
Here is Amazon’s stock performance from 2013 to 2020.
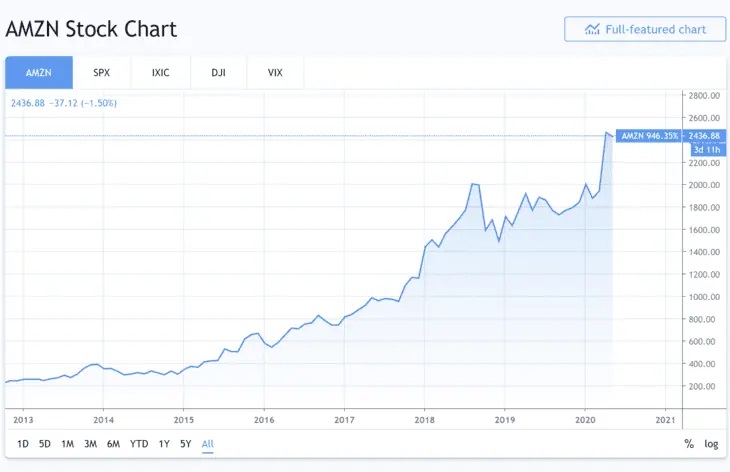
Wow, it is trending up rather smoothly. I’ll design a trading model that invests in Amazon as it trends up.
I then test my trading model on this same dataset (2013 to 2020).
To my non-surprise, the model performs brilliantly and I make a lot of hypothetical monies. You don’t say!
When the trading model is being tested from 2013, it knows what Amazon’s 2014 stock behavior will be because we took into account 2014’s data when designing the trading model.
The model is said to have “looked ahead” into the future.
Thus, there is look-ahead bias in our model. We built a model based on data we were not supposed to know.
In the simplest sense, when training, a model attempts to learn how to map input features (the available data) to the target (what we want to predict).
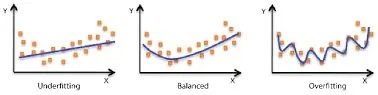
Overfitting is the term used to describe when a model has learnt this relationship “too well” for the training data.
By “too well” we mean rather that it has learnt the relationship too closely- that it sees more trends/correlations/connections than really exist.
We can think of this as a model picking up on too much of the “noise” in the training data- learning to map exact and very specific characteristics of the training data to the target when in reality these were one-off occurrences/connections and not representative of the broader patterns generally present in the data.
As such, the model performs very well for the training data, but flounders comparatively with new data. The patterns developed from the training data do not generalise well to new unseen data.
This is almost always a consequence of making a model too complex- allowing it to have too many rules and/or features relative to the “real” amount of patterns that exist in the data. Its possibly also a consequence of having too many features for the number of observations (training data) we have to train with.
For example in the extreme, imagine we had 1000 pieces of training data and a model that had 1000 “rules”. It could essentially learn to construct rules that stated:
Such a model would perform excellently on the training data, but would probably be nearly useless on any new data that deviated even slightly from the examples that it trained on.
You can read more about overfitting here: What is Overfitting in Trading?
By contrast, underfitting is when a model is too non-specific. I.e., it hasn’t really learnt any meaningful relationships between the training data and the target variable.
Such a model would perform well neither on the training data nor any new data.
This is a rather rarer occurrence in practice than overfitting, and usually occurs because a model is too simple- for example imagine fitting a linear regression model to non-linear data, or perhaps a random forest model with a max depth of 2 to data with many features present.
In general you want to develop a model that captures as many patterns in the training data that exist as possible that still generalise well (are applicable) to new unseen data.
In other words, we want a model that is neither overfitted or underfitted, but just right.
Visit AlgoTrading101 to read on how to train your model.
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from AlgoTrading101 and is being posted with its permission. The views expressed in this material are solely those of the author and/or AlgoTrading101 and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.










Join The Conversation
For specific platform feedback and suggestions, please submit it directly to our team using these instructions.
If you have an account-specific question or concern, please reach out to Client Services.
We encourage you to look through our FAQs before posting. Your question may already be covered!