
- Solve real problems with our hands-on interface
- Progress from basic puts and calls to advanced strategies
Interactive Options Course

Posted April 1, 2024 at 12:06 pm
See Part I for an intro to linear regression and logistic regression.
Logistic regression can be used in trading to predict binary outcomes (stock price will “increase” or decrease”) or classify data based on predictor variables (technical indicators). Here’s an example of how Machine learning logistic regression might be applied in a trading context:
Example: Predicting Stock Price Movement
Suppose a trader wants to predict whether a stock price will increase (1) or decrease (0) based on certain predictor variables or indicators. The trader collects historical data and selects the following predictor variables:
The trader builds a logistic regression model using historical data, where the outcome variable is the binary indicator of whether the stock price increased (1) or decreased (0) on the next trading day.
After training the logistic regression model, the trader can use it to make predictions on new data. For example, if the model predicts a high probability of a stock price increase (p > 0.7) based on past or current data, the trader may decide to buy the stock.
Logistic regression is a versatile statistical method that can be adapted to various types of classification problems. Depending on the nature of the outcome variable and the specific requirements of the analysis, different types of logistic regression models can be employed.
Here are some common types of logistic regression:

Hence, binary logistic regression is used to model the relationship between the predictor variables (an indicator such as RSI, MACD etc.) and the probability of the outcome being in a particular category (“increase” or “decrease” in stock price).
For example, classifying stocks into multiple categories such as “buy,” “hold,” or “sell” based on a set of predictor variables such as fundamental metrics, technical indicators, and market conditions.
For example, analysing the ordinal outcome of trader sentiment or confidence levels (e.g., “low,” “medium,” “high”) based on predictor variables such as market volatility, economic indicators, and news sentiment.
For example, Modelling the binary outcome of stock price movements within different industry sectors (e.g., technology, healthcare, finance) while accounting for the hierarchical structure of the data (stocks nested within sectors).
For example, examining the binary outcome of stock price movements based on both individual-level predictors (such as company-specific factors, technical indicators) and group-level predictors (such as industry sector, market index etc.).
For example, building a binary classification model to predict whether a stock is likely to outperform the market based on a large number of predictor variables while preventing overfitting and selecting the most important features.
Each type of logistic regression has its assumptions, advantages, and limitations, and the choice of the appropriate model depends on the nature of the data, the type of outcome variable, and the specific research or analytical objectives.
Now, let us see the difference between logistic regression and linear regression.
| Feature/Aspect | Linear Regression | Logistic Regression |
| Outcome Type | Continuous where the variable can take any value within a given range (e.g., daily stock price) | Binary or Categorical (e.g., Price is “Up” or “Down”) |
| Prediction | Value prediction. For example, stock price | Probability prediction For example, likelihood of an event |
| Relationship Assumption | Linear, that is, the dependent variable (such as predictive outcome) can be found out with the help of independent variables (such as past values). For example, on the basis of historical data, a trader can predict future prices of stock. | Log-Linear. For example, consider a situation where a quantity grows exponentially over time. A log-linear model would describe the relationship between the logarithm of the quantity and time as linear, implying that the quantity grows or decays at a constant rate on a logarithmic scale. |
| Model Output | Change in outcome per unit change in predictor | Change in log odds per unit change in predictor |
| Applications | Predicting in terms of amounts | Classifying in categories |
In essence:
Logistic regression, like other statistical methods, relies on several key assumptions to ensure the validity and reliability of the results. Here are some of the key assumptions underlying logistic regression:
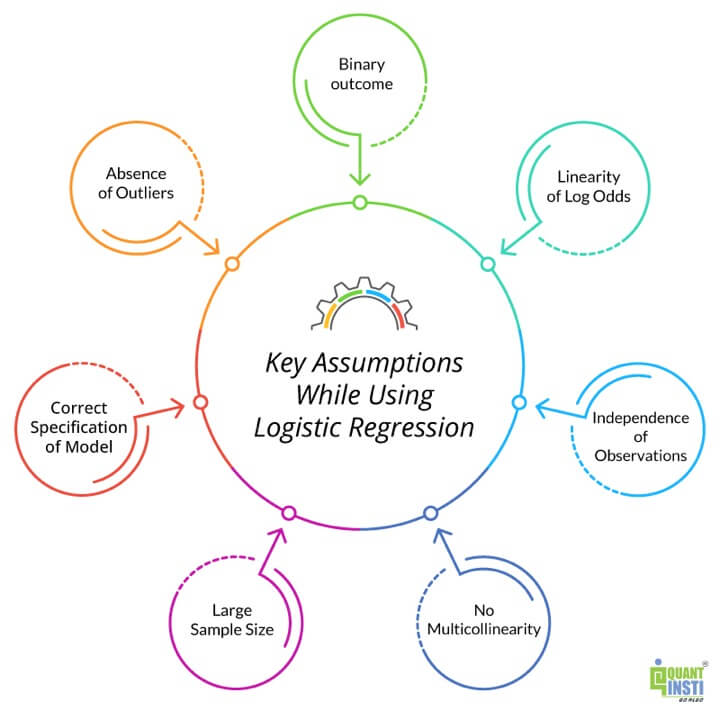
In summary, while logistic regression is a powerful and widely used method for modelling binary outcomes, it is crucial to ensure that the key assumptions of the model are met to obtain valid and reliable results. Violation of these assumptions can lead to biassed estimates, inaccurate predictions, and misleading conclusions, emphasising the importance of careful data preparation, model checking, and interpretation in logistic regression analysis.
Author: Chainika Thakar (Originally written By Vibhu Singh)
Stay tuned for Part III on how to use logistic regression in trading.
Originally posted on QuantInsti blog.
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from QuantInsti and is being posted with its permission. The views expressed in this material are solely those of the author and/or QuantInsti and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.









Join The Conversation
For specific platform feedback and suggestions, please submit it directly to our team using these instructions.
If you have an account-specific question or concern, please reach out to Client Services.
We encourage you to look through our FAQs before posting. Your question may already be covered!