
- Solve real problems with our hands-on interface
- Progress from basic puts and calls to advanced strategies
Interactive Options Course

Posted September 11, 2020 at 9:45 am
Check out the first installment of this series to get started with sentiment analysis.
Consider deploying the Bag of Words method to generate vectors for large documents. The resultant vectors will be of large dimension and will contain far too many null values resulting in sparse vectors. This is also observed in the above sample example.
Apart from resulting in sparse representations, Bag of Words does a poor job in making sense of text data. For example, consider the two sentences: “I love playing football and hate cricket” and it’s vice-versa “I love playing cricket and hate football”. Bag of Words approach will result in similar vectorized representations although both sentences carry different meanings. Attention-based deep learning models like BERT are used to solve the problem of contextual awareness.
We can solve the problem of sparse vectors to some extent using the techniques discussed below:
While tokenizing documents, we may encounter similar words but in different cases, eg: upper ‘CASE’ or lower ‘case’ or title ‘Case’. While the word case is common, different tokens will be generated for them. This increases the size of vocabulary and consequently the dimension of generated word vectors.
Stop words include common occurring words such as ‘the’, ‘is’, etc. Removing such words from vocabulary results in vectors of lesser dimension. Stop words are not exhaustive, and one can specify custom stop words while working on their Bag of Words model.
While the aim of both the techniques is to result in a root word from the original word, the method deployed in doing so is different. Stemming does this by stripping the suffix of words under consideration. For example: ‘playing’ becomes ‘play’ and so on. There is no standard procedure to do stemming and various stemmers are available. Often stemming results in words that do not mean anything. Lemmatization takes a different approach by incorporating linguistics into consideration and results in meaningful root words. This method is relatively difficult as it requires constructing a dictionary to achieve the desired results.
Below is an example of Scikit-learn’s CountVectorizer that has added functionality of removing stop words and converting words into the lower case before coming up with the vectorized representation of documents.
# Import CountVectorizer from sklearn
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(stop_words=’english’, lowercase=True)
word_count = cv.fit_transform(corpus) # Fit the model
print(cv.get_feature_names()) # Print all the words in vocabulary
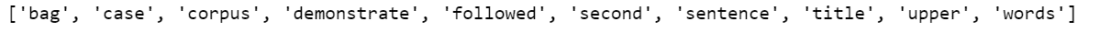
df_ = pd.DataFrame(word_count.toarray(), columns = cv.get_feature_names())
df_ # bag of words vectorized representation

Notice the difference in the number of words in vocabulary as compared to the fundamental approach.
Stay tuned for the next installment in this series, in which the author will discuss Bag of Words vs Word2Vec.
To download the complete Python code, visit QuantInsti: https://blog.quantinsti.com/bag-of-words/
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from QuantInsti and is being posted with its permission. The views expressed in this material are solely those of the author and/or QuantInsti and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.









Join The Conversation
For specific platform feedback and suggestions, please submit it directly to our team using these instructions.
If you have an account-specific question or concern, please reach out to Client Services.
We encourage you to look through our FAQs before posting. Your question may already be covered!