
- Solve real problems with our hands-on interface
- Progress from basic puts and calls to advanced strategies
Interactive Options Course

Posted March 20, 2026 at 11:47 am
The article ‘Cross-Attention for Cross-Asset Applications” was originally published on PredictNow.ai blog.
In the previous blog post, we saw how we can apply self-attention transformers to a matrix of time series features of a single stock. The output of that transformer is a transformed feature vector r of dimension 768 × 1. 768 is the result of 12 × 64: all the lagged features are concatenated / flattened into one vector. 12 is the number of lagged months, and 64 is the dimension of the embedding space for the 52 features we constructed.
What if we have a portfolio of many stocks whose returns we want to predict, or whose allocations we want to optimize? That’s where cross-attention transformers come in. The purpose of cross-attention is that a feature in an asset i may be relevant as a context to a feature of an asset j. Once again, we follow the development by Cong et. al. (2020).
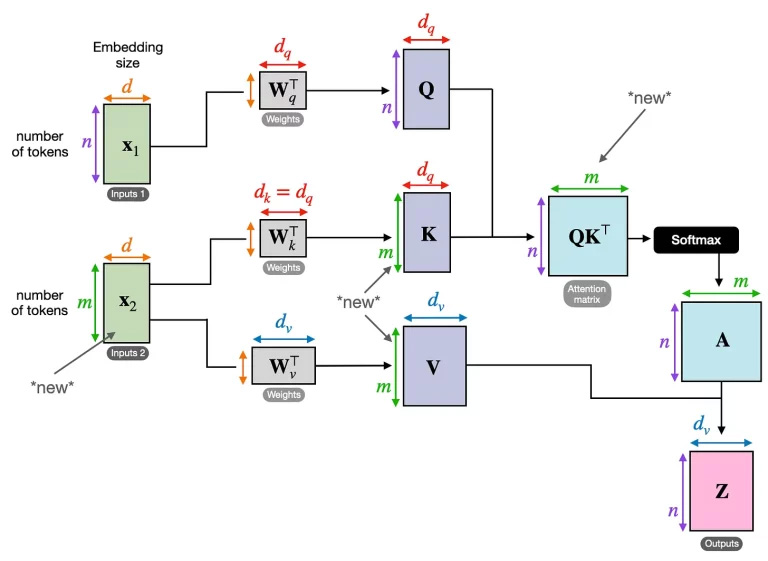
To recap, self-attention transformers take as input one n × d matrix X, with n rows of features and d columns of each feature’s embeddings. A cross-attention transformer takes as input 2 or more such matrices X1, X2, … The common application example of a cross-attention transformer is language translation. E.g. to translate from Chinese (the “key”, or encoder) to English (the “query”, or decoder), we would have
X1 ~ “I am Chinese”, and
X2 ~ “我是中国人”
To be exact, the rows of X1 will actually be a d-dimensional vector embedding (representation) of one of the words in the English sentence, and ditto for the rows of X2 for the words in the Chinese sentence. Note that while the embedding dimension d must be the same for both X1 and X2, they obviously do not need to have the same number of words (i.e. rows).
Source: https://sebastianraschka.com/blog/2023/self-attention-from-scratch.html
X1 (query) is the English sentence. X2 (key and value) is the Chinese sentence.
Now, we can imagine that Xi (query) is asset i’s context vector we called ri in the previous blog post, and Xj (key and value) is asset j’s context vector we called rj which provides the context for asset i’s features. We can next apply the usual linear transformations Wq, Wk, and Wv to mash up their time components to form the Q, K, and V matrices. Then we can use them to compute the cross-attention matrix A using the usual scaled dot product with the softmax function, which AlphaPortfolio calls SATT(i, j) (“Self Attention function”, a misnomer in our opinion). Because the Q’s and K’s are just 768 × 1 vectors in our case, each (i, j) element of SATT is just a scalar. So the SATT matrix is just another cross-attention matrix, and each row i represents the normalized weights given by features j=1, 2, …, I, including j=i, where I is the number of assets. The context vector given an attention matrix SATT is, as usual,
(AlphaPortfolio calls this a(i), an attenuation score. But we prefer to describe this as a context vector Z(i) because we are multiplying an attention matrix with an input vector v.)
Voilà! Once you have the context vector, it is like a superpowered input feature vector that captures all manners of time-series and cross-sectional information about the portfolio that you can use for downstream applications. In the case of AlphaPortfolio, the authors use Z(i) as the state variables for a deep reinforcement learning (DRL) program to find the best allocations to the stocks. It is essentially a stock selection program with a side of optimal capital allocation. In the next blog post, we will dissect one of these DRL programs.
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from PredictNow.ai and is being posted with its permission. The views expressed in this material are solely those of the author and/or PredictNow.ai and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.











Join The Conversation
For specific platform feedback and suggestions, please submit it directly to our team using these instructions.
If you have an account-specific question or concern, please reach out to Client Services.
We encourage you to look through our FAQs before posting. Your question may already be covered!