
- Solve real problems with our hands-on interface
- Progress from basic puts and calls to advanced strategies
Interactive Options Course

Posted May 12, 2025 at 12:00 pm
The post “From Logistic to Random Forests: Mastering Non-linear Regression Models” was originally published on QuantInsti blog.
Ever wish you had a crystal ball for the financial markets? While we can’t quite do that, regression is a super useful tool that helps us find patterns and relationships hidden in data – it’s like being a data detective!
The most common starting point is linear regression, which is basically about drawing the best straight line through data points to see how things are connected. Simple, right?
In Part 1 of this series, we explored ways to make those line-based models even better, tackling things like curvy relationships (Polynomial Regression) and messy data with too many variables (using Ridge and Lasso Regression). We learned how to refine those linear predictions.
But what if a line (even a curvy one) just doesn’t fit? Or what if you need to predict something different, like a “yes” or “no”?
Get ready for Part 2, my friend! Where we venture beyond the linear world and explore a fascinating set of regression techniques designed for different kinds of problems:
Let’s dive into these powerful tools and see how they can unlock new insights from financial data!
Hey there! Before we get into the good stuff, it helps to be familiar with a few key concepts. You can still follow along intuitively, but brushing up on these will give you a much better understanding. Here’s what to check out:
1. Statistics and Probability
Know the essentials—mean, variance, correlation, and probability distributions. New to this? Probability Trading is a great intro.
2. Linear Algebra Basics
Basics like matrices and vectors are super useful, especially for techniques like Principal Component Regression.
3. Regression Fundamentals
Get comfy with linear regression and its assumptions. Linear Regression in Finance is a solid starting point.
4. Financial Market Knowledge
Terms like stock returns, volatility, and market sentiment will come up a lot. Statistics for Financial Markets can help you brush up.
5. Explore Part 1 of This Series
Check out Part 1 for an overview of Polynomial, Ridge, Lasso, Elastic Net, and LARS. It’s not mandatory, but it provides excellent context for different regression types.
Once you’re good with these, you’ll be all set to dive deeper into how regression techniques reveal insights in finance. Let’s get started!
At its core, regression analysis models the relationship between a dependent variable (the outcome we want to predict) and one or more independent variables (predictors).
Think of it as figuring out the connection between different things – for instance, how does a company’s revenue (the outcome) relate to how much they spend on advertising (the predictor)? Understanding these links helps you make educated guesses about future outcomes based on what you know.
When that relationship looks like a straight line on a graph, we call it linear regression – nice and simple!
Good question! In Part 1, we mentioned that ‘linear’ in regression refers to how the model’s coefficients are combined.
Non-linear models, like the ones we’re exploring here, break that rule. Their underlying equations or structures don’t just add up coefficients multiplied by predictors in a simple way. Think about Logistic Regression using that S-shaped curve (sigmoid function) to squash outputs between 0 and 1, or Decision Trees making splits based on conditions rather than a smooth equation, or SVR using ‘kernels’ to handle complex relationships in potentially higher dimensions.
These methods fundamentally work differently from linear models, allowing them to capture patterns and tackle problems (like classification or modelling specific data segments) that linear models often can’t.
You use Logistic regression when the dependent variable (here, a dichotomous variable) is binary (think of it as a “yes” or “no” outcome, like a stock going up or down). It helps predict the binary outcome of an occurrence based on the given data.
It is a non-linear model that gives a logistic curve with values limited to between 0 and 1. This probability is then compared to a threshold value of 0.5 to classify the data. So, if the probability for a class is more than 0.5, we label it as 1; otherwise, it is 0.
This model is generally used to predict the performance of stocks.
Note: You can not use linear regression here because it could give values outside the 0 to 1 range. Also, the dependent variable can take only two values here, so the residuals won’t be normally distributed about the predicted line.
Want to learn more? Check out this blog for more on logistic regression and how to use Python code to predict stock movement.
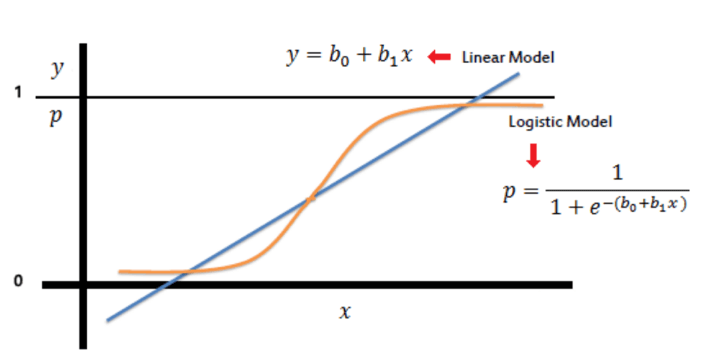
Source: https://www.saedsayad.com/logistic_regression.htm
Traditional linear regression models predict the mean of a dependent variable based on independent variables. However, financial time series data often contain skewness and outliers, making linear regression unsuitable.
To solve this problem, Koenker and Bassett (1978) introduced quantile regression. Instead of modeling just the mean, it helps us see the relationship between variables at different points (quantiles and percentiles) in the dependent variable’s distribution, such as:
It estimates different quantiles (like medians or quartiles) of the dependent variables for the given independent variables, instead of just the mean. We call these conditional quantiles.
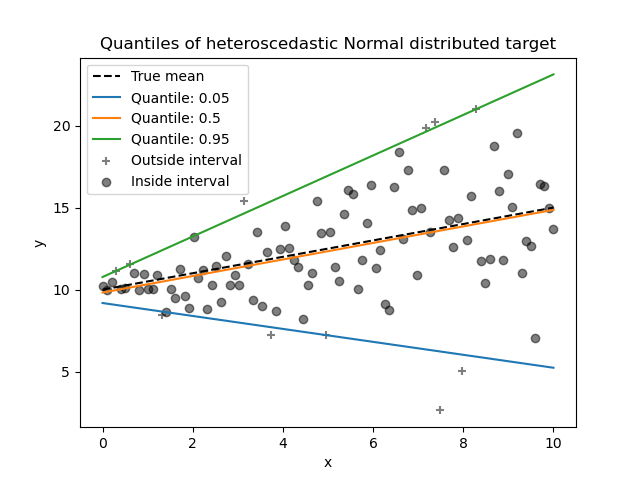
Source: https://scikit-learn.org/stable/auto_examples/linear_model/plot_quantile_regression.html
Like OLS regression coefficients, which show the changes from one-unit changes of the predictor variables, quantile regression coefficients show the changes in the specified quantile from one-unit changes in the predictor variables.
Advantages:
Let’s look at an example to better understand how quantile regression works:
Let’s say you’re trying to understand how the overall “mood” of the market (measured by a sentiment index) affects the daily returns of a particular stock. Traditional regression would tell you the average impact of a change in sentiment on the average stock return.
But what if you’re particularly interested in extreme movements? Quantile regression is used here:
So, instead of just one average effect, quantile regression gives you a more complete picture of how market sentiment influences different parts of the stock’s return distribution, especially the potentially risky extreme losses. Isn’t that great?
Imagine trying to predict a numerical value – like the price of something or a company’s future revenue. A Decision Tree offers an intuitive way to do this, working like a flowchart or a game of ‘yes/no’ questions.
A decision tree is divided into smaller and smaller subsets based on certain conditions related to the predictor variables. Think of it like this:
Decision trees start with your entire dataset and progressively splits it into smaller and smaller subsets at the nodes, thereby creating a tree-like structure. Each of the nodes where the data is split based on a condition is called an internal/split node, and the final subsets are called the terminal/leaf nodes.
In finance, decision trees may be used for classification problems like predicting whether the prices of a financial instrument will go up or down.

Source: https://blog.quantinsti.com/decision-tree/
Decision Tree Regression is when we use a decision tree to predict continuous values (like the price of a house or temperature) instead of categories (like predicting yes/no or up/down).
Here’s how it works in regression:
So, the tree splits the data into groups, and each group gets a fixed number as the prediction.
Things to Watch Out For:
You have a full description of the model in this blog and its use in trading in this blog.
To learn more about decision trees in trading check out this Quantra course.
Let’s see a situation where this might be a useful tool:
Imagine you’re trying to predict a company’s sales revenue for the next quarter. You have data on its past performance and factors like: marketing spend in the current quarter, number of salespeople, the company’s industry sector (e.g., Tech, Retail, Healthcare), etc.
The tree might ask:
“Marketing spend > $500k?” If yes, “Industry = Tech?”. Based on the path taken, you land on a leaf.
The prediction for a new company following that path would be the average revenue of all past companies that fell into that same leaf (e.g., the average revenue for tech companies with high marketing spend).
Remember how individual Decision Trees can sometimes be a bit unstable or might overfit the training data? What if we could harness the power of many decision trees instead of relying on just one?
That’s the idea behind Random Forest Regression!
It’s an “ensemble” method, meaning it combines multiple models (in this case, decision trees) to achieve better performance than any single one could alone. You can think of it using the “wisdom of the crowd” principle: instead of asking one expert, you ask many, slightly different experts and combine their insights. Generally, Random Forests perform significantly better than individual decision trees (Breiman, 2001).
How does the forest get “random”?
The “random” part of Random Forest comes from two key techniques used when building the individual trees:
Making Predictions (Regression = Averaging)
To predict a value for new data, you run it through every tree in the forest. Each tree gives its own prediction. The Random Forest’s final prediction is simply the average of all those individual tree predictions. This averaging smooths things out and makes the model much more stable.
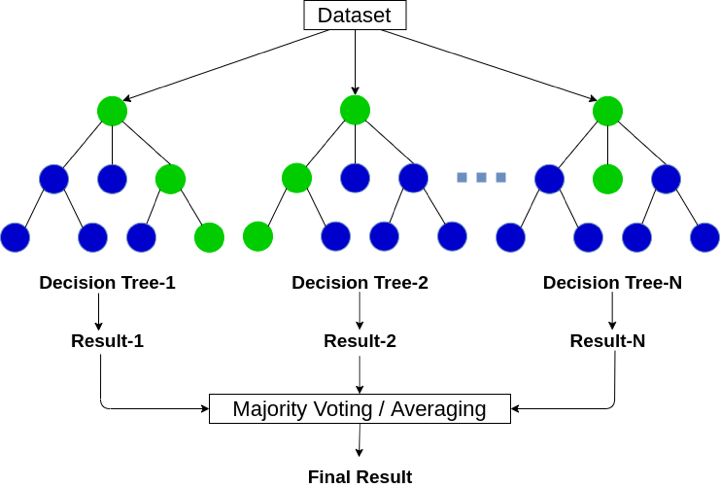
Image representation of a Random forest regressor: Source: https://ai-pool.com/a/s/random-forests-understanding
Why Use Random Forest Regression?
Things to Consider:
Check out this post if you want to learn more about random forests and how they can be used in trading.
Think we’d leave you hanging? No way!
Here’s an example to help you better understand how random forests work in practice:
You want to predict how much a stock’s price will swing (its volatility) next month, using data like recent volatility, trading volume, and market fear (VIX index).
A single decision tree might latch onto a specific pattern in the past data and give a jumpy prediction. A Random Forest approach is more robust:
It builds hundreds of trees. Each tree sees slightly different historical data and considers different feature combinations at each split. Each tree estimates the volatility. The final prediction is the average of all these estimates, giving a more stable and reliable forecast of future volatility than one tree alone could provide.
You might be familiar with Support Vector Machines (SVM) for classification. Support Vector Regression (SVR) takes the core ideas of SVM and applies them to regression tasks – that is, predicting continuous numerical values.
SVR approaches regression a bit differently than many other methods. While methods like standard linear regression try to minimize the error between the predicted and actual values for all data points, SVR has a different philosophy.
The Epsilon (ε) Insensitive Tube:
Imagine you’re trying to fit a line (or curve) through your data points. SVR tries to find a “tube” or “street” around this line with a certain width, defined by a parameter called epsilon (ε). The goal is to fit as many data points as possible inside this tube.
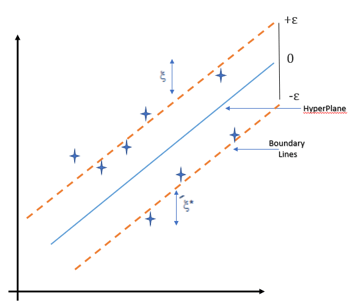
Image representation of Support vector regression: Source: https://www.educba.com/support-vector-regression/
Here’s the key idea: For any data points that fall inside this ε-tube, SVR considers the prediction “good enough” and ignores their error. It only starts penalizing errors for points that fall outside the tube. This makes SVR less sensitive to small errors compared to methods that try to get every point perfect. The regression line (or hyperplane in higher dimensions) runs down the middle of this tube.
Handling Curves (Non-Linearity):
What if the relationship between your predictors and the target variable isn’t straight? SVR uses a “kernel trick”. This is like projecting the data into a higher-dimensional space where a complex, curvy relationship might look like a simpler straight line (or flat plane). By finding the best “tube” in this higher dimension, SVR can effectively model non-linear patterns. Common kernels include linear, polynomial, and RBF (Radial Basis Function). The best choice depends on the data.
Pros:
Cons:
The explanation for the whole model can be found here.
And if you want to learn more about how support vector machines can be used in trading, be sure to check out this blog, my friend!
By now, you probably know how this works, so let’s look at a real-life example that uses SVR:
Think about predicting the price of a stock option (like a call or put). Option prices depend on several complex, non-linear factors: the underlying stock’s price, time left until expiration, expected future volatility (implied volatility), interest rates, etc.
SVR (especially with a non-linear kernel like RBF) is suitable for this. It can capture these complex relationships using the kernel trick. The ε-tube focuses on getting the prediction within an acceptable small range (e.g., predicting the price +/- 5 cents), rather than stressing about tiny deviations for every single option.
| Regression Model | One-Line Summary | One-Line Use Case |
| Logistic Regression | Predicts the probability of a binary outcome. | Predicting whether a stock will go up or down. |
| Quantile Regression | Models relationships at different quantiles of the dependent variable’s distribution. | Understanding how market sentiment affects extreme stock price movements. |
| Decision Trees Regression | Predicts continuous values by partitioning data into subsets based on predictor variables. | Predicting a company’s sales revenue based on various factors. |
| Random Forest Regression | Improves prediction accuracy by averaging predictions from multiple decision trees. | Predicting the volatility of a stock. |
| Support Vector Regression (SVR) | Predicts continuous values by finding a “tube” that best fits the data. | Predicting option prices, which depend on several non-linearly related factors. |
And that concludes our tour through the more diverse landscapes of regression! We’ve seen how Logistic Regression helps us tackle binary predictions, how Quantile Regression gives us insights beyond the average, especially for risk, and how Decision Trees and Random Forests offer intuitive yet powerful ways to model complex, non-linear relationships. Finally, Support Vector Regression provides a unique, margin-based approach practical even in high-dimensional spaces.
From the refined linear models in Part 1 to the varied techniques explored here, you now have a much broader regression toolkit at your disposal. Each model has its strengths and is suited for different financial questions and data challenges.
The key takeaway? Regression is not a one-size-fits-all solution. Understanding the nuances of different techniques allows you to choose the right tool for the job, leading to more insightful analysis and powerful predictive models.
And as you continue learning my friend, don’t just stop at theory. Keep exploring, keep practicing with real data, and keep refining your skills. Happy modeling!
Perhaps you’re keen on a complete, holistic understanding of regression applied directly to trading? In that case, check out this Quantra course.
If you’re serious about taking your skills to the next level, consider QuantInsti’s EPAT program—a solid path to mastering financial algorithmic trading.
With the right training and guidance from industry experts, it can be possible for you to learn it as well as Statistics & Econometrics, Financial Computing & Technology, and Algorithmic & Quantitative Trading. These and various aspects of Algorithmic trading are covered in this algo trading course. EPAT equips you with the required skill sets to build a promising career in algorithmic trading. Be sure to check it out.
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from QuantInsti and is being posted with its permission. The views expressed in this material are solely those of the author and/or QuantInsti and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.









Join The Conversation
For specific platform feedback and suggestions, please submit it directly to our team using these instructions.
If you have an account-specific question or concern, please reach out to Client Services.
We encourage you to look through our FAQs before posting. Your question may already be covered!