- Solve real problems with our hands-on interface
- Progress from basic puts and calls to advanced strategies
Interactive Options Course

Posted September 9, 2022 at 11:33 am
The human mind is an amazing place. Umpteen ideas originate there in a split second, coloured with various emotions. Many such thoughts and emotions are splattered across the ‘walls’ and ‘feeds’ of increasingly popular social media platforms.
In the quest to find the elusive alpha, data scientists and quant analysts have now shifted their focus on processing the tons of ‘big data’ churned out there by internet users. Using programs to understand and analyse the human language is called natural language processing (NLP).
In this post, we’ll look at one of the popular libraries for natural language processing in Python- spaCy.
The topics we will cover are:
spaCy is a free, open-source library for natural language processing in Python. It is one of the two most popular libraries for NLP, the other one being NLTK. We will look at the important differences between the two in a later section.
The spaCy website describes it as the preferred tool for “industrial strength natural language processing”. The rich features offered by spaCy make it an excellent choice for NLP, information extraction, and natural language understanding.
The key advantage of spaCy is that it is designed to work with large amounts of data in an optimal and robust manner.
The simplest way to install spaCy is to follow the following steps:
Note: If you are doing the installation from a Jupyter notebook, don’t forget to prefix the commands with a ‘!’ sign.
Natural Language Toolkit (NLTK) is the largest natural language processing library that supports many languages. Let us compare NLTK and spaCy.
| S.No. | NLTK | spaCy |
| 1. | NLTK is primarily designed for research. | spaCy is designed for production use. |
| 2. | NLTK provides support for many languages. | Currently, spaCy provides trained pipelines for 23 languages and supports 66+ languages. |
| 3. | NLTK follows a string processing approach and has a modular architecture. | spaCy follows an object-oriented approach. |
| 4. | NLTK provides a large number of different NLP algorithms and hence is preferred for research and building innovative solutions. The user can select a particular algorithm from the available options for a particular task. | spaCy uses the best algorithm for a particular task. The user does not have to select an algorithm. |
| 5. | NLTK can be slower. | spaCy is optimized for speed. |
| 6. | It is built using Python. | It is built using Cython. |

Source: https://spacy.io/
spaCy introduces the concept of pipelines. When you pass a text through a pipeline, it goes through different steps (or pipes) of processing. The output from one step (or pipe) is fed into the next step (or pipe).
spaCy offers many trained pipelines for different languages. Typically, a trained pipeline includes a tagger, a lemmatizer, a parser, and an entity recognizer.
We can also design our own custom pipelines in spaCy.
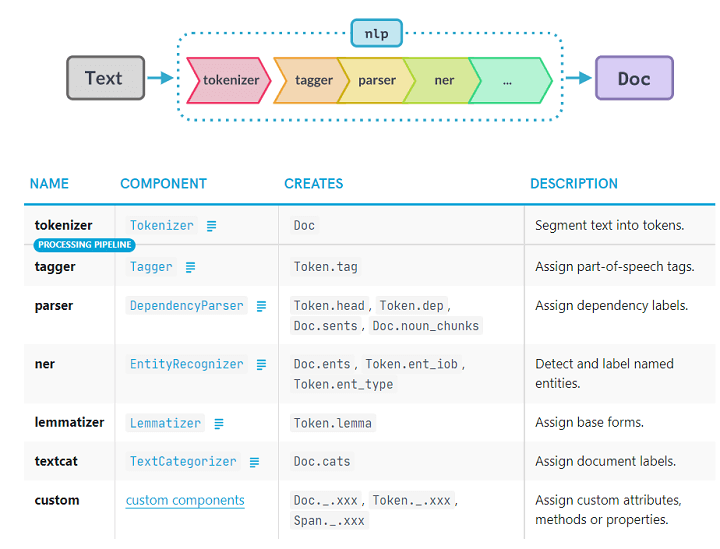
Source: https://spacy.io/usage/processing-pipelines
Let us now do some natural language processing and see how some of these components work in the next few sections.
We need to have installed spaCy and the trained model that we want to use. In this blog, we will be working with the model for the English language, the en_core_web_sm.
Passing a text to a trained model produces the doc container. Though it may appear to be similar to the text, the doc contains valuable metadata related to the text.
Yes, I know! You can’t spot any difference between the text and the doc from the above code snippet. But let us explore a bit more.
Okay, so the length is different. What else? Let us now print the tokens from the doc.
The output for the above line of code is:
Jennifer
is
learning
quantitative
analysis.
We have now seen that the doc container contains tokens. Tokens are the basic building blocks of the spaCy NLP ecosystem. They may be a word or a punctuation mark.
Tokenization is the process of breaking down a text into words, punctuations, etc. This is done using the rules for the specific language whose model we are using.
The tokens have different attributes, which are the foundation of natural language processing using spaCy. We will look at some of these in the following sections.
A lemma is the base form of a token, with no inflectional suffixes. E.g., the lemma for ‘going’ and ‘went’ will be ‘go’. This process of deducing the lemma of each token is called lemmatization.
Output:
I – I
am – be
going – go
where – where
Jennifer – Jennifer
went – go
yesterday – yesterday
. – .
Stay tuned for the next installment, in which Udisha Alok will show how to split text into sentences using spaCy.
Visit QuantInsti website for additional insight on this topic: https://blog.quantinsti.com/spacy-python/.
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from QuantInsti and is being posted with its permission. The views expressed in this material are solely those of the author and/or QuantInsti and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.









Join The Conversation
For specific platform feedback and suggestions, please submit it directly to our team using these instructions.
If you have an account-specific question or concern, please reach out to Client Services.
We encourage you to look through our FAQs before posting. Your question may already be covered!